Découvrez comment ChatGPT, ce génial chatbot alimenté par l’intelligence artificielle, apprend à devenir de plus en plus futé ! De son fonctionnement mystérieux à ses limites surmontées grâce à RLHF, plongeons dans le monde fascinant de l’apprentissage des machines. Mais attention, les problèmes d’alignement dans les grands modèles de langage peuvent nous réserver quelques surprises ! Heureusement, ChatGPT a plus d’un tour dans son sac et utilise RLHF pour les contrer. Prêts à explorer les avantages et inconvénients de cette approche révolutionnaire ? Alors, attachez vos ceintures et embarquez pour un voyage au cœur de l’intelligence artificielle.
Découvrez ChatGPT : votre compagnon de conversation intelligent
Imaginez un instant que vous avez un ami qui peut parler n’importe quelle langue, comprendre n’importe quel sujet et adapter son discours à n’importe quel style. Cet ami s’appelle ChatGPT. Créé par OpenAI, ChatGPT est un modèle de langue ultra sophistiqué qui dépasse ses prédécesseurs en termes de précision, de détails et de cohérence.
Son secret ? Une concentration intense sur les conversations interactives. Mais ce n’est pas tout : l’équipe derrière ChatGPT a utilisé une combinaison ingénieuse d’apprentissage supervisé et d’apprentissage par renforcement pour peaufiner le modèle. Cela signifie que ChatGPT est constamment en train d’apprendre et de s’améliorer grâce à une boucle de feedbacks humains.
Un outil clé dans ce processus de formation est le Reinforcement Learning from Human Feedback (RLHF), une technique avancée qui permet de minimiser les sorties nuisibles, trompeuses et biaisées qui peuvent survenir avec les modèles de langue traditionnels. Avec le RLHF, ChatGPT est affiné pour produire des réponses qui sont non seulement précises, mais aussi utiles et éthiques.
En combinant ces techniques d’apprentissage avancées avec une focalisation sur les conversations interactives, ChatGPT se positionne comme un outil de communication puissant et polyvalent. Que vous cherchiez à rédiger un courriel professionnel, à générer des idées pour un roman ou simplement à discuter de vos intérêts personnels, ChatGPT est prêt à vous aider.
Quelles sont les limites de GPT-3 et comment RLHF les surmonte-t-il ?
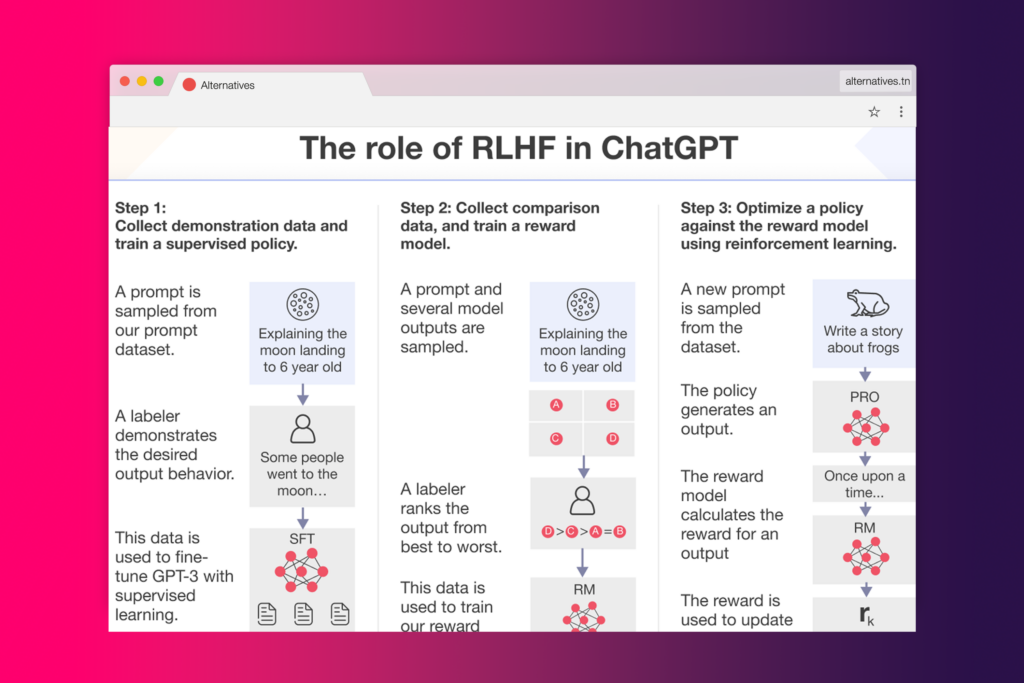
Imaginez un artiste peintre doué qui peut reproduire à la perfection des œuvres d’art existantes, mais qui, lorsqu’il s’agit de créer des œuvres originales, échoue à produire des images qui correspondent aux attentes des spectateurs. C’est une analogie qui illustre les défis de GPT-3, un modèle de langage de pointe. Alors que GPT-3 peut générer des textes d’une précision humaine étonnante, il rencontre des difficultés lorsqu’il s’agit de produire des résultats alignés sur les attentes humaines et les valeurs souhaitables.
Pourquoi cela se produit-il? Eh bien, les limitations de GPT-3 découlent de son processus d’entraînement. L’IA, comme notre peintre hypothétique, a été formée sur d’immenses quantités de données textuelles provenant d’Internet. De ce fait, elle peut générer du texte qui ressemble à celui d’un humain, mais ses sorties peuvent ne pas toujours correspondre à ce qu’un humain attend ou juge souhaitable.
Alors, comment surmonter ces limitations? Ici entre en scène RLHF (Reinforcement Learning from Human Feedback), ou apprentissage par renforcement à partir de rétroactions humaines. Cette technique utilise les commentaires humains dans la boucle d’entraînement pour minimiser les sorties nuisibles, inexactes et/ou biaisées. En d’autres termes, elle permet à ChatGPT de mieux s’aligner sur les préférences humaines, prenant ainsi le contrôle du pinceau et guidant notre artiste pour qu’il crée des œuvres d’art qui plaisent vraiment aux spectateurs.
En conclusion, alors que GPT-3 est un modèle de langage puissant, il a ses limitations. Cependant, grâce à l’approche innovante de l’apprentissage par renforcement à partir de rétroactions humaines, ChatGPT est en mesure de surmonter ces défis, offrant ainsi des résultats plus précis et alignés sur les attentes humaines.
Qu’est-ce que la capacité et l’alignement dans l’apprentissage des machines ?
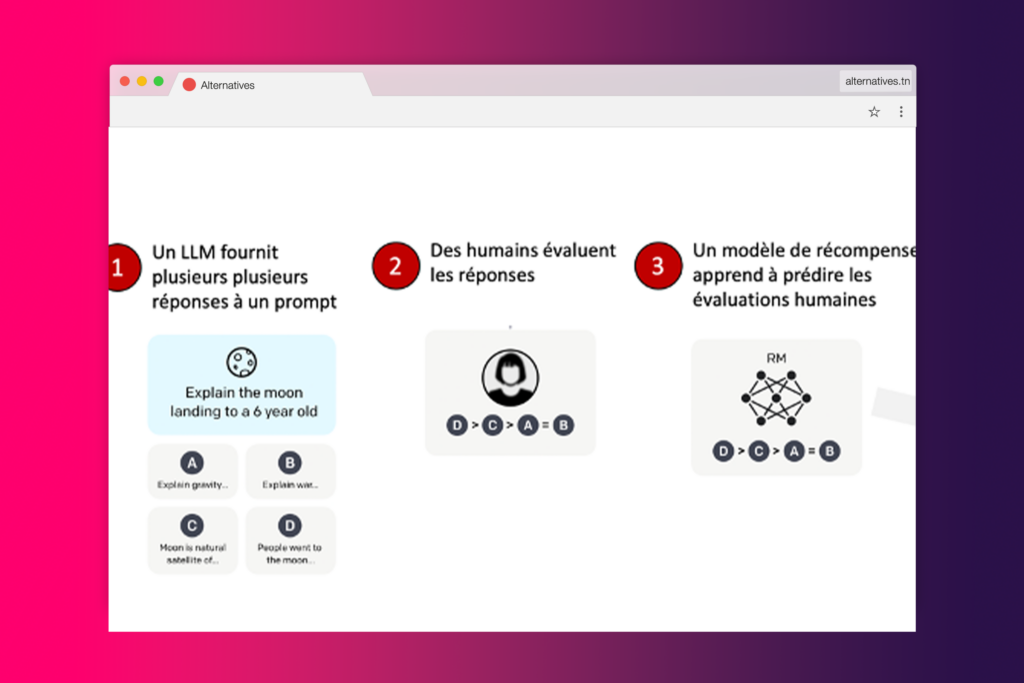
Imaginez que vous construisiez une machine. C’est excitant, non ? Mais avant d’aller plus loin, laissez-moi vous poser deux questions essentielles : Que voulez-vous que votre machine fasse exactement ? Et comment mesurerez-vous sa performance ? Dans le monde de l’apprentissage des machines, ces deux questions sont encapsulées par deux concepts clés : la capacité et l’alignement.
La capacité fait référence à la compétence d’un modèle à accomplir des tâches spécifiques. Imaginez que votre machine soit un modèle d’apprentissage automatique destiné à prédire le mouvement des prix des actions en bourse. Si elle est capable de prédire avec précision ces mouvements, elle serait considérée comme ayant une grande capacité pour cette tâche. Cette capacité est évaluée en fonction de la manière dont elle optimise sa fonction objective. Dans ce cas, la fonction objective pourrait être une mesure comme la perte logarithmique (log loss), qui mesure la différence entre la distribution de probabilité prédite par le modèle et la distribution réelle.
Passons maintenant à la deuxième question. L’alignement s’interroge sur ce que nous voulons réellement que le modèle fasse par rapport à ce qu’il est entraîné à faire. Il demande : “La fonction objective du modèle est-elle en adéquation avec nos intentions ?” Par exemple, si vous souhaitez que votre modèle d’apprentissage automatique améliore la vie des gens en leur fournissant des informations précises et opportunes, mais qu’il se concentre plutôt sur la prédiction des mouvements de prix des actions, alors il y a un désalignement.
Un désalignement se produit lorsque le modèle est capable d’optimiser l’objectif d’entraînement mais est mal aligné sur l’objectif ultime. C’est un défi courant dans des domaines comme les systèmes de dialogue ou les assistants personnels intelligents. Ces modèles puissants et complexes entraînés sur d’énormes quantités de données sont devenus extrêmement compétents ces dernières années, mais lorsqu’ils sont utilisés dans des systèmes de production pour faciliter la vie humaine, ils ne répondent souvent pas à ce potentiel. Le problème d’alignement est donc un thème central dans l’apprentissage des machines.
A lire aussi : Les 10 meilleures écoles d’avocat en France pour devenir un expert en droit
Quels sont les problèmes d’alignement dans les grands modèles de langage ?
Les grands modèles de langage, tels que GPT-3, sont des goliaths de l’intelligence artificielle, formés sur d’immenses quantités de données textuelles issues de l’Internet. Avec leur capacité à générer du texte qui ressemble de près à celui créé par des humains, on pourrait penser qu’ils sont parfaitement alignés avec nos attentes. Cependant, la réalité est plus nuancée. Il existe un écart, une divergence, entre la façon dont GPT-3 est formé et la façon dont nous, en tant qu’humains, aimerions l’utiliser. Cette divergence est ce que nous appelons le problème d’alignement.
En effet, les problèmes d’alignement se manifestent par une divergence entre leur formation et leur application dans des scénarios réels. Par exemple, un modèle de langage comme GPT peut ne pas suivre les instructions explicites données par l’utilisateur, montrant ainsi un manque d’aide ou d’alignement.
Imaginez une situation où vous demandez à votre assistant personnel intelligent de vous rappeler un rendez-vous important. Au lieu de cela, il commence à réciter des poèmes de Robert Frost. C’est peut-être un exemple exagéré, mais il illustre bien le défi de l’alignement.
En outre, ce désalignement devient un problème lorsque GPT-3 est utilisé dans des applications qui nécessitent confiance et fiabilité, comme les systèmes de dialogue ou les assistants personnels intelligents. Malgré leurs capacités, les grands modèles de langage tombent souvent à court lorsque utilisés dans des systèmes de production pour faciliter la vie des humains. Ils peuvent générer du texte humain, mais leur sortie peut ne pas toujours s’aligner avec les attentes humaines ou les valeurs souhaitables.
Le problème de désalignement se produit également lorsque le modèle peine à généraliser des tâches ou des contextes qui nécessitent une compréhension plus profonde du langage. Les chercheurs et les développeurs travaillent sur diverses approches pour résoudre le problème d’alignement dans les grands modèles de langage.
ChatGPT, par exemple, est basé sur le modèle original GPT-3, mais a été davantage formé en utilisant des rétroactions humaines pour guider le processus d’apprentissage avec une intention spécifique. C’est une manière d’attaquer le problème de l’alignement.
A lire aussi : Détecter ChatGPT : Les meilleurs outils pour identifier ce phénomène
Quelles sont les conséquences du problème d’alignement ?
Imaginez un instant que vous utilisez un assistant personnel intelligent pour faciliter votre quotidien. Vous attendez de lui qu’il suive vos instructions à la lettre, n’est-ce pas ? Malheureusement, les grands modèles de langage comme GPT peuvent parfois ne pas suivre les instructions explicites données par l’utilisateur, entraînant un manque de serviabilité. C’est comme si vous demandiez à votre assistant de vous aider à préparer un gâteau au chocolat, mais qu’il vous donne la recette d’un gâteau à la vanille à la place. Frustrant, n’est-ce pas ?
Mais ce n’est pas tout. Parfois, GPT peut générer des faits qui n’existent pas ou qui sont faux. Nous appelons ce phénomène les hallucinations. Imaginez que vous demandiez à votre assistant de vous donner des informations sur une espèce d’oiseau en voie d’extinction. Au lieu de cela, il vous parle d’une espèce d’oiseau qui n’existe pas. Vous seriez non seulement confus, mais vous pourriez aussi finir par propager de fausses informations.
Ensuite, il y a le manque d’interprétabilité. C’est comme si vous demandiez à votre assistant pourquoi il pleut et qu’il vous répondait simplement “Parce que le ciel est triste”. Vous vous demanderiez probablement comment il est arrivé à cette conclusion. Et bien, c’est le même défi que nous avons avec GPT. Il est difficile de comprendre comment il arrive à une décision ou à une prédiction spécifique.
Enfin, il y a la possibilité que GPT produise des sorties biaisées ou toxiques. Si GPT est formé sur des données biaisées ou toxiques, il peut produire des sorties qui reflètent ces biais, même sans instruction explicite. C’est comme si vous demandiez à votre assistant de vous aider à rédiger une lettre de motivation, mais qu’il vous conseillait d’utiliser un langage offensant ou discriminatoire. Ce serait non seulement inapproprié, mais cela pourrait aussi vous causer des problèmes.
En somme, le problème d’alignement dans les grands modèles de langage comme GPT peut avoir des conséquences graves. Il est donc essentiel de trouver des solutions pour y remédier.
Au cœur de l’évolution de ChatGPT se trouve une technique innovante : le Reinforcement Learning from Human Feedback (RLHF), ou Apprentissage par Renforcement à partir des Retours Humains. Cette stratégie audacieuse a été conçue spécifiquement pour faire face aux défis d’alignement inhérents aux grands modèles linguistiques.
Pour comprendre comment cela fonctionne, il faut d’abord comprendre que ChatGPT est une version améliorée du modèle original GPT-3. S’appuyant sur les fondements de ce dernier, les créateurs de ChatGPT ont intégré les retours humains dans le processus d’apprentissage du modèle. C’est là que RLHF entre en jeu, en servant de boussole pour guider ChatGPT dans son apprentissage.
En effet, ChatGPT est le premier modèle à utiliser RLHF en production. C’est une avancée significative dans le domaine de l’intelligence artificielle, car elle permet d’attaquer frontalement le problème d’alignement. Les retours humains agissent comme un guide, aidant le modèle à s’aligner plus étroitement sur nos préférences et nos valeurs.
Il est important de souligner que l’utilisation de RLHF ne se limite pas à la rectification des problèmes d’alignement. Cette technique joue également un rôle crucial dans la minimisation des sorties nuisibles, non véridiques et biaisées de ChatGPT. En d’autres termes, RLHF aide à rendre les interactions avec ChatGPT plus sûres, plus authentiques et plus utiles pour nous, les utilisateurs.
En conclusion, le secret de la réussite de ChatGPT réside dans son utilisation innovante des retours humains pour résoudre le problème d’alignement. Grâce à l’utilisation de RLHF, ChatGPT est non seulement capable de comprendre notre langage, mais aussi d’apprendre de nos préférences et de nos valeurs.
Découvrez de plus: Concurrents de ChatGPT : Top 10 Sites comme Chat GPT pour les Codeurs
Quels sont les avantages et les inconvénients de l’utilisation de RLHF dans ChatGPT ?
Le Reinforcement Learning from Human Feedback (RLHF), ou apprentissage par renforcement à partir des retours humains, est une méthode avancée qui a été employée pour calibrer ChatGPT en fonction des préférences humaines. Cette technique a permis de surmonter certains défis inhérents aux modèles de langage à grande échelle, tels que l’incapacité à comprendre le contexte ou à produire des réponses biaisées. Cependant, comme toute technologie, l’utilisation du RLHF dans ChatGPT présente aussi son lot de limites.
L’une des limites majeures réside dans le fait que les préférences des étiqueteurs, des chercheurs et des développeurs jouent un rôle déterminant dans le processus d’apprentissage de ChatGPT. En d’autres termes, le modèle de langage s’aligne sur les valeurs et les préférences de ceux qui participent activement à sa formation. Cela signifie que le biais des étiqueteurs est intégré dans la formation du modèle de récompense et l’évaluation du modèle.
Le biais des étiqueteurs est intégré dans la formation du modèle de récompense et l’évaluation du modèle.
Il est important de noter que les étiqueteurs et les chercheurs impliqués dans le processus de formation peuvent ne pas représenter tous les utilisateurs finaux potentiels du modèle de langue. Ainsi, bien que le modèle puisse être optimisé pour refléter les préférences d’un groupe spécifique, il peut ne pas être aussi efficace pour répondre aux besoins d’une audience plus large ou plus diverse.
En conclusion, bien que le RLHF offre des avantages indéniables pour l’amélioration de l’alignement de ChatGPT, il est essentiel de prendre en compte ses limites et de continuer à chercher des façons d’optimiser et d’améliorer cette technologie.
Quelles sont les références sélectionnées pour une lecture plus approfondie ?
Dans notre quête incessante de connaissances, l’exploration ne se termine jamais. Alors que nous avons abordé le fonctionnement de ChatGPT et comment il utilise le RLHF pour résoudre les problèmes d’alignement, il est évident que le sujet est vaste et complexe. C’est là que notre section consacrée aux références sélectionnées pour une lecture plus approfondie prend tout son sens.
En tant que lecteur avide et curieux, vous vous demandez peut-être où vous pouvez trouver plus d’informations sur ces sujets fascinants. Vous serez ravis de savoir que cette section contient une mine d’informations, soigneusement sélectionnées pour vous aider à approfondir votre compréhension du ChatGPT et du RLHF.
Les références que nous avons choisies pour vous sont susceptibles d’être liées au contenu de l’article. Il s’agit de ressources complémentaires, allant des livres aux articles, en passant par des travaux de recherche et d’autres sources pertinentes. Ces références ont été sélectionnées pour leur pertinence et leur qualité, dans le but de vous fournir des informations précises et à jour.
En fournissant ces références, nous ne faisons pas que partager des informations. Nous créons un pont entre vous et le monde vaste et fascinant de l’apprentissage automatique, vous invitant à explorer et à découvrir par vous-même. Après tout, la meilleure façon d’apprendre est souvent de se plonger dans le sujet.
Que vous soyez un expert cherchant à affiner ses connaissances ou un novice avide d’en savoir plus, ces références sont là pour vous guider dans votre voyage de découverte. Alors, préparez-vous, car votre exploration du monde de ChatGPT et du RLHF ne fait que commencer.
Lire aussi >> Comment fonctionne Chat GPT : Découvrez les secrets de ce modèle révolutionnaire de traitement du langage
